Semantic Search
Overview
Before starting on this tutorial, we recommend checking out the previous tutorial on training a custom Q&A model on an index of documents.
We will now go a step further, and see how we can use the SliceX AI pre-trained semantic search API on a database of documents, by simply generating the embeddings corresponding to the this index. This feature will let you play around with new and interesting Q&A use cases in a faster and more affordable manner- without needing to run training jobs from scratch each time!
Dataset Processing
We will try out this semantic search tutorial on the Wikipedia Movie Plots dataset (hosted here on Kaggle). The dataset includes 34,886 plot summaries of movies from around the world, along with descriptive entries like release year, director, cast and genre in different columns:
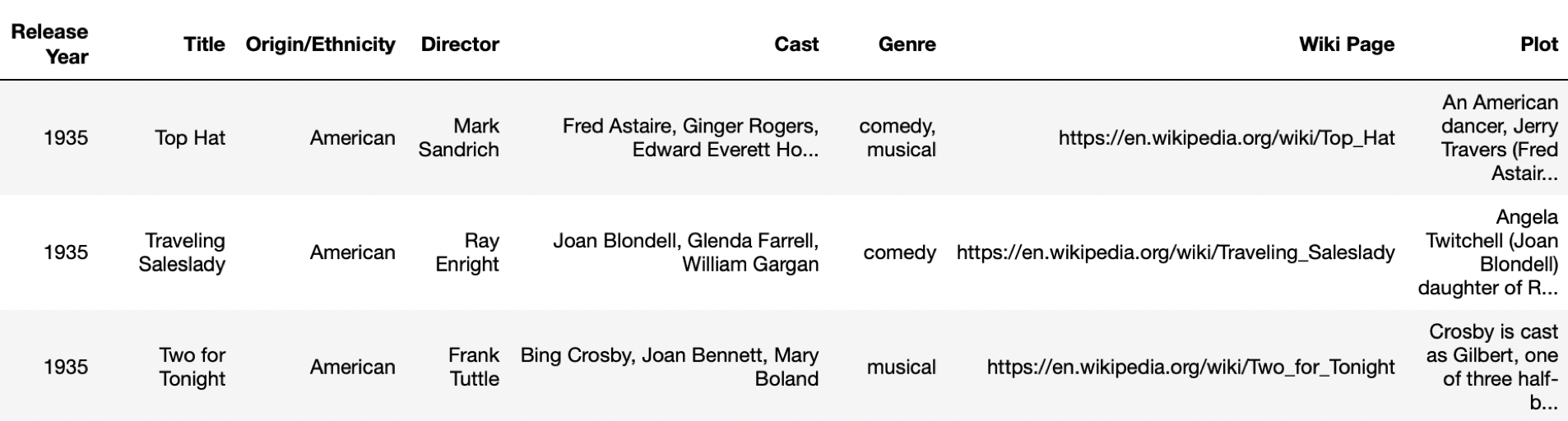 To adapt the dataset to a question-answering format that we will need for the semantic search API, we will utilize these column entry headers to compose natural language queries. While the descriptive column entries and plot summary will provide the contextual answers to these queries. These question-context pairs will compose the training dataset.
To adapt the dataset to a question-answering format that we will need for the semantic search API, we will utilize these column entry headers to compose natural language queries. While the descriptive column entries and plot summary will provide the contextual answers to these queries. These question-context pairs will compose the training dataset.
Here is a sample code that can help with generating the train and validation data to generate the embeddings:
import json
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
df=pd.read_csv('wiki_movie_plots_deduped.csv')
df.fillna("unknown",inplace=True)
df['q1']="What year was the movie "+df.Title+" released?"
df['q2']="What is the origin/ethnicity of the movie "+df.Title+" ?"
df['q3']="Who is the director of the movie "+df.Title+" ?"
df['q4']="Which genre does the movie "+df.Title+" belong to ?"
df['q5']="Who are the cast members of the movie "+df.Title+" ?"
df['q6']="What is the plot of the movie "+df.Title+" ?"
df['a1']="The movie "+df.Title+" was released in the year "+df['Release Year'].astype(str)+" ."
df['a2']="The origin/ethnicity of the movie "+df.Title+" is "+df['Origin/Ethnicity']+" ."
df['a3']="The director of the movie "+df.Title+" is "+df.Director+" ."
df['a4']="The movie "+df.Title+" belongs to the "+df.Genre+" genre."
df['a5']="The cast members of the movie "+df.Title+" are "+df.Cast+" ."
df['a6']="The plot summary of the movie "+df.Title+" is: "+df.Plot
df = pd.concat(
[
df[["q1", "a1"]],
df[["q2", "a2"]],
df[["q3", "a3"]],
df[["q4", "a4"]],
df[["q5", "a5"]],
df[["q6", "a6"]],
]
)
df.fillna("",inplace=True)
df['question']=df.q1+df.q2+df.q3+df.q4+df.q5+df.q6
df['context']=df.a1+df.a2+df.a3+df.a4+df.a5+df.a6
movie_df=df[['question','context']].reset_index(drop=True)
movie_df.head()
Our formatted data now looks like this:

We also need to generate the label_id.json and config.json files that are part of the training data packet:
#shuffling the dataset with a random seed
movie_df = movie_df.sample(
frac=1,
random_state=1
).reset_index(drop=True)
movie_df.drop_duplicates(subset='question',inplace=True)
train_ratio = 0.8
# train and val split
train_df, dev_df = train_test_split(movie_df, test_size=1 - train_ratio, shuffle=False)
dev_df=dev_df.reset_index(drop=True)
# dumping the df into the train.json and dev.json
train_df[['question','context']].to_json(path_or_buf='wiki-movie-qa/train.json',orient='index')
dev_df[['question','context']].to_json(path_or_buf='wiki-movie-qa/dev.json',orient='index')
dict_labels = dict(zip(movie_df.index,movie_df.context))
# dumping the dict-labels into a json file that's stored in the wiki-movie-qa folder
with open("wiki-movie-qa/label_id.json", "w") as outfile:
json.dump(dict_labels, outfile)
We now have all the necessary bits and pieces for generating the embeddings for this dataset. Zip up all the into a folder, and let’s get on to launching custom training to generate the embeddings.
Custom Training
The model family for Q&A jobs is Dragonfruit. An example request you can use to launch an embeddings job is:
import requests
headers = {
"Content-Type": "application/json",
"x-api-key": "API_KEY",
}
data = {
"type": "embedding",
"model_config": {
"name": "wiki-movie",
"type": "question-answering",
"family": "Dragonfruit",
"size": "mini"
},
"dataset_url": 'URL'
}
response = requests.post(
"https://api.slicex.ai/trainer/language/training-jobs",
headers=headers,
json=data,
)
print(response.json())
You should get a response that looks like this:
{"id":"MODEL_ID"}
This is your MODEL_ID. Make sure to note it. You will now be using it for monitoring and custom inference.
Monitoring the training job
You can monitor your training job and check performance stats with a GET request to this endpoint (you will need your MODEL_ID to retrieve logs for the right job):
import requests
headers = {
'Content-Type': 'application/json',
'x-api-key': 'API_KEY',
}
response = requests.get(
'https://api.slicex.ai/trainer/language/models/MODEL_ID',
headers=headers,
)
print(response.json())
Here is an example response you will see when the job has completed:
{'data': {'id': 'MODEL_ID', 'app_id': 'API_KEY', 'name': 'wiki-movie', 'training_status': 'READY', 'type': 'question-answering', 'modality': 'language', 'created': '2022-09-08T06:04:49.785272+00:00', 'training_cost': 1.0}}
Custom inference
Your custom semantic search API is now ready to use. You can POST requests to the predictor endpoint with the MODEL_ID to generate responses to custom queries.